前言
文章性质:学习笔记 📖
学习资料:吴茂贵《 Python 深度学习基于 PyTorch ( 第 2 版 ) 》【ISBN】978-7-111-71880-2
主要内容:根据学习资料撰写的学习笔记,该篇主要介绍了单 GPU 加速和多 GPU 加速,以及使用 GPU 的注意事项。
预:关于 GPU 加速
深度学习涉及很多向量或多矩阵运算,如矩阵相乘、矩阵相加、矩阵-向量乘法等。深层模型的算法,如 BP 、自编码器、CNN 等,都可以写成矩阵运算的形式,而无须写成循环运算。然而,在单核 CPU 上执行时,矩阵运算会被展开成循环的形式,本质上还是串行执行。GPU(Graphic Process Unit,图形处理器)的众核体系结构包含几千个流处理器,可将矩阵运算并行化执行,大幅缩短计算时间。随着 NVIDIA 、AMD 等公司不断推进其 GPU 的大规模并行架构,面向通用计算的 GPU 已成为加速可并行应用程序的重要手段。得益于 GPU 众核(Many-Core)体系结构,程序在 GPU 系统上的运行速度相较于单核 CPU 往往提升几十倍乃至上千倍。
目前,GPU 已经发展到了较为成熟的阶段。利用 GPU 来训练深度神经网络,可以充分发挥其计算核心的能力,使得在使用海量训练数据的场景下所耗费的时间大幅缩短,占用的服务器也更少。如果对深度神经网络进行合理优化,一块 GPU 卡相当于数十甚至上百台 CPU 服务器的计算能力,因此 GPU 已经成为业界在深度学习模型训练方面的首选解决方案。
如何使用 GPU ?现在很多深度学习工具都支持 GPU 运算,使用时只需要简单配置即可。PyTorch 支持 GPU,可以通过 to(device) 函数来将数据从内存中转移到 GPU 显存,如果有多个 GPU ,还可以定位到哪个或哪些 GPU ?PyTorch 一般把 GPU 作用于张量或模型(包括 torch.nn 下面的一些网络模型以及自己创建的模型)等数据结构上。
一、单 GPU 加速
使用 GPU 之前,需要确保 GPU 是可用的,可以通过 torch.cuda.is_available() 的返回值来进行判断。返回 True 则表示具有能够使用的 GPU 。 通过 torch.cuda.device_count() 可以获得可用的 GPU 的数量。
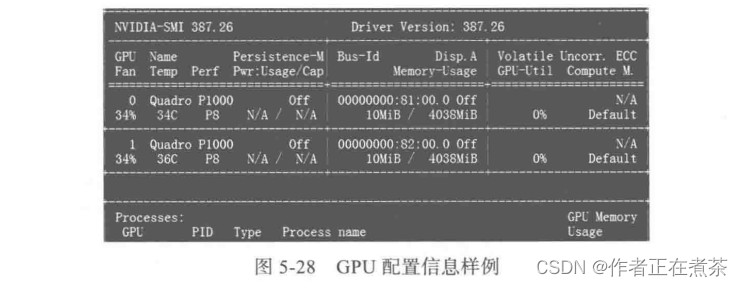
如何查看平台 GPU 的配置信息?在命令行输入命令 nvidia-smi 即可(适合于 Linux 或 Windows 环境),如图 5-28 所示。
把数据从内存转移到 GPU ,通常针对 张量(我们需要的数据)和 模型 。
1. 对于类型为 FloatTensor 或 LongTensor 等的张量,我们直接使用方法 .to(device) 或 .cuda() 即可。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 或 device = torch.device("cuda:0")
device1 = torch.device("cuda:1")
for batch_idx, (img, label) in enumerate(train_loader):
img = img.to(device)
label = label.to(device)2. 对于模型来说,也使用 .to(device) 或 .cuda() 方法来将网络放到 GPU 显存中。
# 实例化网络
model = Net()
model.to(device) # 使用序号为 0 的 GPU
# 或 model.to(device1) # 使用序号为 1 的 GPU二、多 GPU 加速
这里我们介绍单主机多 GPU 的情况,单主机多 GPU 主要采用的是 DataParallel 函数,而不是 DistributedParallel,后者一般用于多主机多 GPU ,当然也可用于单主机多 GPU 。使用多 GPU 训练的方式有很多,前提是我们的设备中存在两个及以上 GPU 。使用时直接用模型传入 torch.nn.DataParallel 函数即可,代码如下:
# 对于模型
net = torch.nn.DataParallel(model)这时,默认所有存在的显卡都会被使用。如果你的电脑有很多显卡,但只想利用其中的部分,例如,只使用编号为 0 、1 、3 、4 的四个 GPU ,那么可以采用以下方式:
# 假设有 4 个 GPU ,其 id 设置如下
device_ids = [0, 1, 2, 3]
# 对于数据
input_data = input_data.to(device=device_ids[0])
# 对于模型
net = torch.nn.DataParallel(model)
net.to(device)或者:
os.environ["CUDA_VISIBLE_DEVICES"] = ','.join(map(str, [0, 1, 2, 3]))
net = torch.nn.DataParallel(model)说明:其中的 CUDA_VISIBLE_DEVICES 表示当前可以被 PyTorch 程序检测到的 GPU 。
下面为单机多 GPU 的实现代码:
1)背景说明。以波士顿房价数据为例,共 506 个样本,13 个特征。数据划分成训练集和测试集,然后用 data.DataLoader 将数据转换为可批加载的方式。采用 nn.DataParallel 并发机制,环境有 2 个 GPU 。当然,数据量很小,按理不宜用 nn.DataParallel 。
2)加载数据。
boston = load_boston()
X, y = (boston.data, boston.target)
dim = X.shape[1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 组合训练数据及标签
myset = list(zip(X_train, y_train))3)把数据转换为批处理加载方式。批次大小为 128 ,打乱数据。
from torch.utils import data
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
dtype = torch.FloatTensor
train_loader = data.DataLoader(myset, batch_size=128, shuffle=True)4)定义网络。
class Net1(nn.Module):
"""
使用 Sequential() 函数构建网络,Sequential()函数的功能是将网络的层组合到一起
"""
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super(Net1, self).__init__()
self.layer1 = torch.nn.Sequential(nn.Linear(in_dim, n_hidden_1))
self.layer2 = torch.nn.Sequential(nn.Linear(n_hidden_1, n_hidden_2))
self.layer3 = torch.nn.Sequential(nn.Linear(n_hidden_2, out_dim))
def forward(self, x):
x1 = F.relu(self.layer1(x))
x1 = F.relu(self.layer2(x1))
x2 = self.layer3(x1)
# 显示每个 GPU 分配的数据大小
print("\tIn Model: input size", x.size(), "output size", x2.size())
return x25)把模型转换为多 GPU 并发处理格式。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 实例化网络
model = Net1(13, 16, 32, 1)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs")
# dim = 0 [64, xxx] -> [32, ...], [32, ...] on 2GPUs
model = nn.DataParallel(model)
model.to(device)运行的结果如下:

6)选择优化器及损失函数。
optimizer_orig = torch.optim.Adam(model.parameters(), lr=0.01)
loss_func = torch.nn.MSELoss()7)模型训练,并可视化损失值。
from torch.utils.tensorboard import SummaryWriter
# from tensorboardX import SummaryWriter
writer = SummaryWriter(log_dir='logs')
for epoch in range(100):
model.train()
for data, label in train_loader:
input = data.type(dtype).to(device)
label = label.type(dtype).to(device)
output = model(input)
loss = loss_func(output, label)
# 反向传播
optimizer_orig.zero_grad()
loss.backward()
optimizer_orig.step()
print("Outside: input size", input.size(), "output_size", output.size())
writer.add_scalar('train_loss_paral', loss, epoch)运行的部分结果如下:

从运行结果可以看出,一个批次数据( batch-size=128 )拆分成两份,每份大小为 64 ,分别放在不同的 GPU 上。此时用 GPU 监控也可以发现两个 GPU 同时在使用,如图 5-29 所示。

8)通过 Web 页面查看损失值的变化情况,如图 5-30 所示。
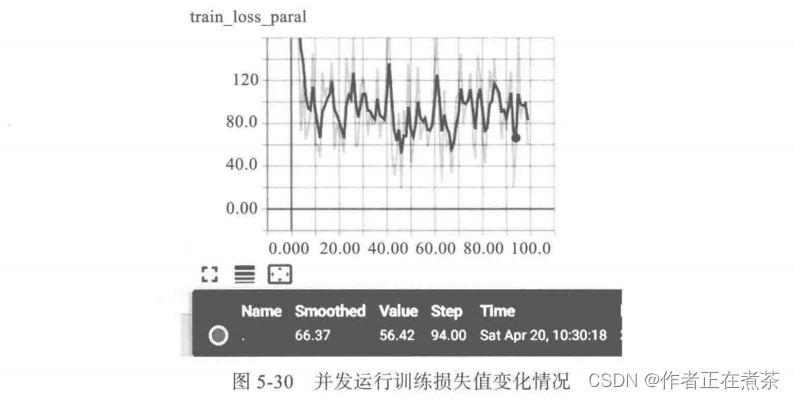
图形中出现较大振幅是由于采用批次处理,而且数据没有做任何预处理,因此对数据进行规范化应该更平滑一些。
单主机多 GPU 也可使用 DistributedParallel 函数,虽然配置比使用 nn.DataParallel 函数稍微麻烦一点,但是训练速度和效果更好。
具体配置为:
# 初始化使用 nccl 后端
torch.distributed.init_process_group(backend="nccl")
# 模型并行化,使用多进程,可单机或分布式训练
model = torch.nn.parallel.DistributedDataParallel(model)单主机运行时,使用下列方法启动:
python -m torch.distributed.launch main.py参考代码:feiguyunai/Python-DL-PyTorch2/pytorch-05/pytorch-05-05.ipynb at main · Wumg3000/feiguyunai · GitHub
三、使用 GPU 的注意事项
使用 GPU 可以提升训练的速度,但如果使用不当,可能影响使用效率,具体注意事项如下:
• GPU 的数量尽量为偶数,奇数个 GPU 可能会出现异常中断的情况;
• GPU 训练速度很快,但数据量较小时,效果可能没有单 GPU 好,甚至还不如 CPU ;
• 如果内存不够大,使用多 GPU 训练的时候可通过设置 pin_memory 为 False,当然有时使用精度稍低的数据类型的效果也还行。
第五章の小结
本章从机器学习的概念出发,首先说明其基本任务、一般流程等,然后说明在机器学习中解决过拟合、欠拟合的一些常用技巧或方法。同时介绍了各种激活函数、损失函数、优化器等机器学习、深度学习的核心内容。最后说明在程序中如何设置 GPU 设备、如何用 GPU 加速训练模型等内容。这章是深度学习的基础。





![[图解]DDD领域驱动设计浮夸,Eric Evans开了个坏头](https://img-blog.csdnimg.cn/direct/6c700640c7d34013b5adcb3f2058973c.png)